TokenHMR:
Advancing Human Mesh Recovery with
a Tokenized Pose Representation
(CVPR 2024)
1Max Planck Institute for Intelligent Systems, Tubingen, Germany
2Meshcapade 3ETH Zurich
arXiv Paper Code Video Poster Contact
Existing methods that regress 3D human pose and shape (HPS) from an image (like HMR2.0) estimate bodies that are either image-aligned or have accurate 3D pose, but not both. We show that this is a fundamental trade-off for existing methods. Our method, TokenHMR, introduces a novel loss, Threshold-Adaptive Loss Scaling (TALS), and a discrete token-based pose representation of 3D pose. With these, TokenHMR achieves state-of-the-art accuracy on multiple in-the-wild 3D benchmarks.
Abstract
We address the problem of regressing 3D human pose and shape from a single image, with a focus on 3D accuracy. The current best methods leverage large datasets of 3D pseudo-ground-truth (p-GT) and 2D keypoints, leading to robust performance. With such methods, we observe a paradoxical decline in 3D pose accuracy with increasing 2D accuracy. This is caused by biases in the p-GT and the use of an approximate camera projection model. We quantify the error induced by current camera models and show that fitting 2D keypoints and p-GT accurately causes incorrect 3D poses. Our analysis defines the invalid distances within which minimizing 2D and p-GT losses is detrimental. We use this to formulate a new loss “Threshold-Adaptive Loss Scaling” (TALS) that penalizes gross 2D and p-GT losses but not smaller ones. With such a loss, there are many 3D poses that could equally explain the 2D evidence. To reduce this ambiguity we need a prior over valid human poses but such priors can introduce unwanted bias. To address this, we exploit a tokenized representation of human pose and reformulate the problem as token prediction. This restricts the estimated poses to the space of valid poses, effectively providing a uniform prior. Extensive experiments on the EMDB and 3DPW datasets show that our reformulated keypoint loss and tokenization allows us to train on in-the-wild data while improving 3D accuracy over the state-of-the-art. Our models and code will be available for research.
Method Overview
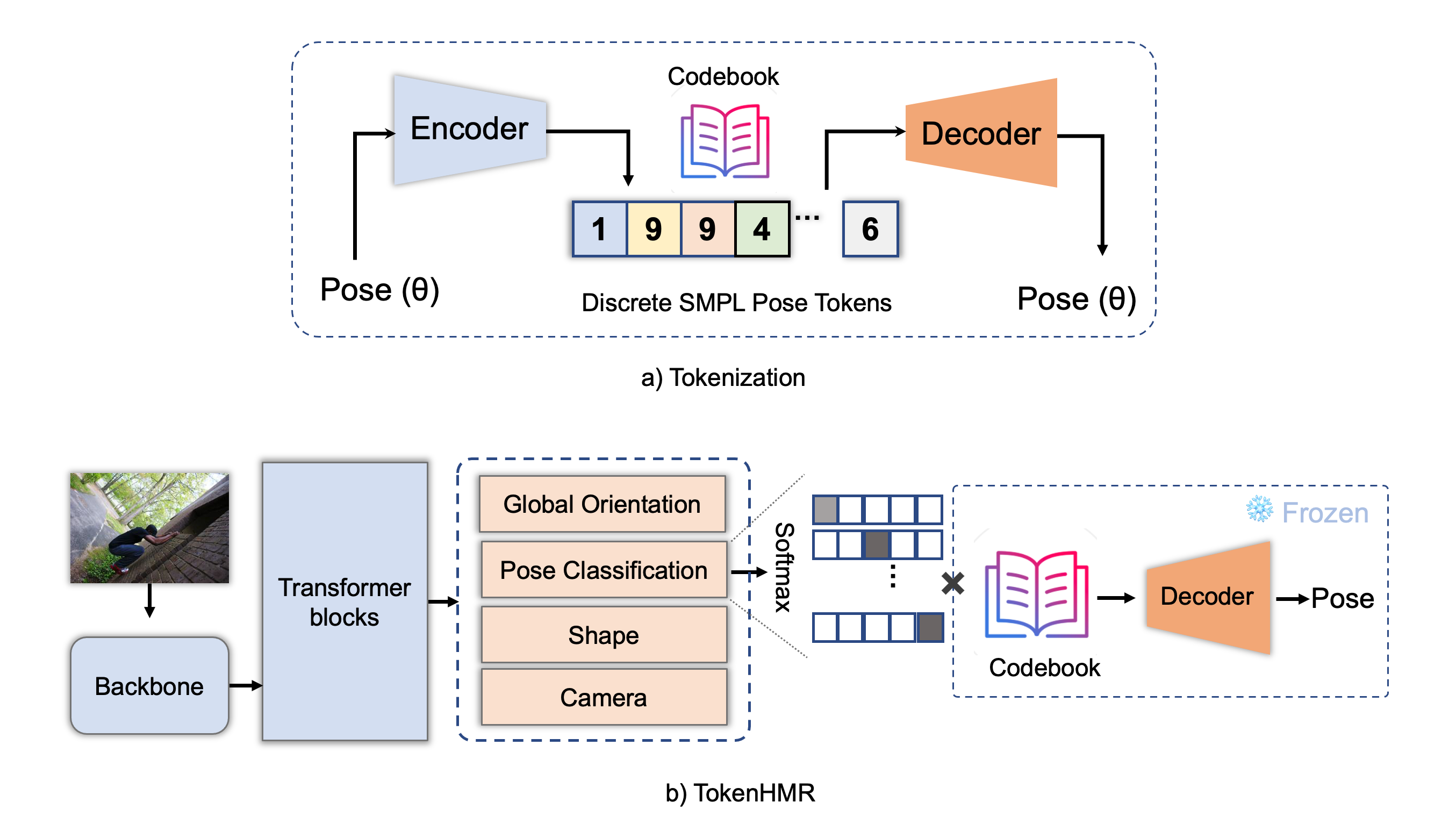
Our method has two stages. (a) In tokenization step, the encoder learns to map continuous pose to discrete pose tokens and the decoder tries to reconstruct the original pose. The uniform prior is encoded in the codebook. (b) During training the TokenHMR model, we use pre-trained decoder which provides a “vocabulary” of valid poses without imposing biases.
Video
Citation
@conference{dwivedi_cvpr2024_tokenhmr,
title = {{TokenHMR}: Advancing Human Mesh Recovery with a Tokenized Pose Representation},
author = {Dwivedi, Sai Kumar and Sun, Yu and Patel, Priyanka and Feng, Yao and Black, Michael J.},
booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {March},
year = {2024},
}